실무에서 여전히 가장 많이 다루는 데이터 소스 중 하나는 파일이다. 금융 거래 내역이 담긴 CSV, 기관 간 데이터 교환에 쓰이는 고정 길이(Fixed-Length) 파일, 그리고 서버의 복잡한 로그 파일들이 그 예다.
만약 개발자가 직접 Java I/O 라이브러리로 대용량 파일을 처리하려 한다면 리소스 누수(File Handler), 메모리 과부하(OutOfMemoryError), 트랜잭션 단위의 롤백 등 이른바 '지옥문'이 열리기 쉽다.
스프링 배치는 이러한 고통을 해결하기 위해 FlatFileItemReader라는 강력한 무기를 제공한다. 이번 포스팅에서는 파일 처리의 아키텍처부터 실무 사례별 설정법까지 낱낱이 파헤쳐 본다.
1. 파일 처리의 심장: 내부 아키텍처 해부
FlatFileItemReader는 파일을 한 줄씩 읽어 우리가 지정한 도메인 객체로 변환한다. 이 마법 같은 과정은 LineMapper라는 인터페이스를 중심으로 한 2단계 작전으로 수행된다.
🔍 객체 매핑 2단계 프로세스

- 토큰화(Tokenization): LineTokenizer가 한 줄의 문자열을 의미 있는 필드(Token) 단위로 분리하여 FieldSet 객체에 담는다.
- 객체 매핑: FieldSetMapper가 FieldSet에 담긴 문자열 데이터들을 자바 객체의 프로퍼티 타입에 맞게 변환하여 꽂아 넣는다.
2. 구분자로 분리된 파일 읽기 (Delimited File)
쉼표(,)나 탭(\t)으로 필드를 구분하는 CSV 형식이 대표적이다. FlatFileItemReaderBuilder를 사용하면 복잡한 설정 없이 간결하게 구현할 수 있다.
💻 실전 코드: 시스템 장애 로그(CSV) 처리
@Bean
@StepScope
public FlatFileItemReader<SystemFailure> systemFailureItemReader(
@Value("#{jobParameters['inputFile']}") String inputFile) {
return new FlatFileItemReaderBuilder<SystemFailure>()
.name("systemFailureItemReader")
.resource(new FileSystemResource(inputFile)) // 대상 파일 지정
.delimited() // [핵심] 구분자 모드 활성화 (DelimitedLineTokenizer 사용)
.delimiter(",") // 구분자 설정 (기본값은 쉼표)
.names("errorId", "errorDateTime", "severity", "processId", "errorMessage") // FieldSet에 부여할 이름
.targetType(SystemFailure.class) // 변환할 대상 클래스
.linesToSkip(1) // 첫 줄(헤더) 건너뛰기
.comments("#") // 주석(#)으로 시작하는 라인 무시
.strict(true) // 파일 미존재 시 배치를 즉시 중단할지 여부
.build();
}
- targetType(): Java의 타입 소거(Type Erasure) 때문에 런타임에 실제 인스턴스를 생성하기 위해 클래스 정보를 명시해야 한다.
- strict 설정: true인 경우 파일 누락이나 데이터 필드 개수 불일치 시 ItemStreamException을 던져 시스템을 보호한다.
3. 칼같이 자른 고정 길이 파일 읽기 (Fixed-Length)
구분자 없이 정해진 위치와 길이만 존재하는 레거시 시스템이나 메인프레임 환경의 데이터를 처리할 때 사용한다. 여기서는 공백이 데이터가 아닌 '자리 맞추기' 용도로 쓰인다.
💻 실전 코드: Range를 활용한 슬라이싱
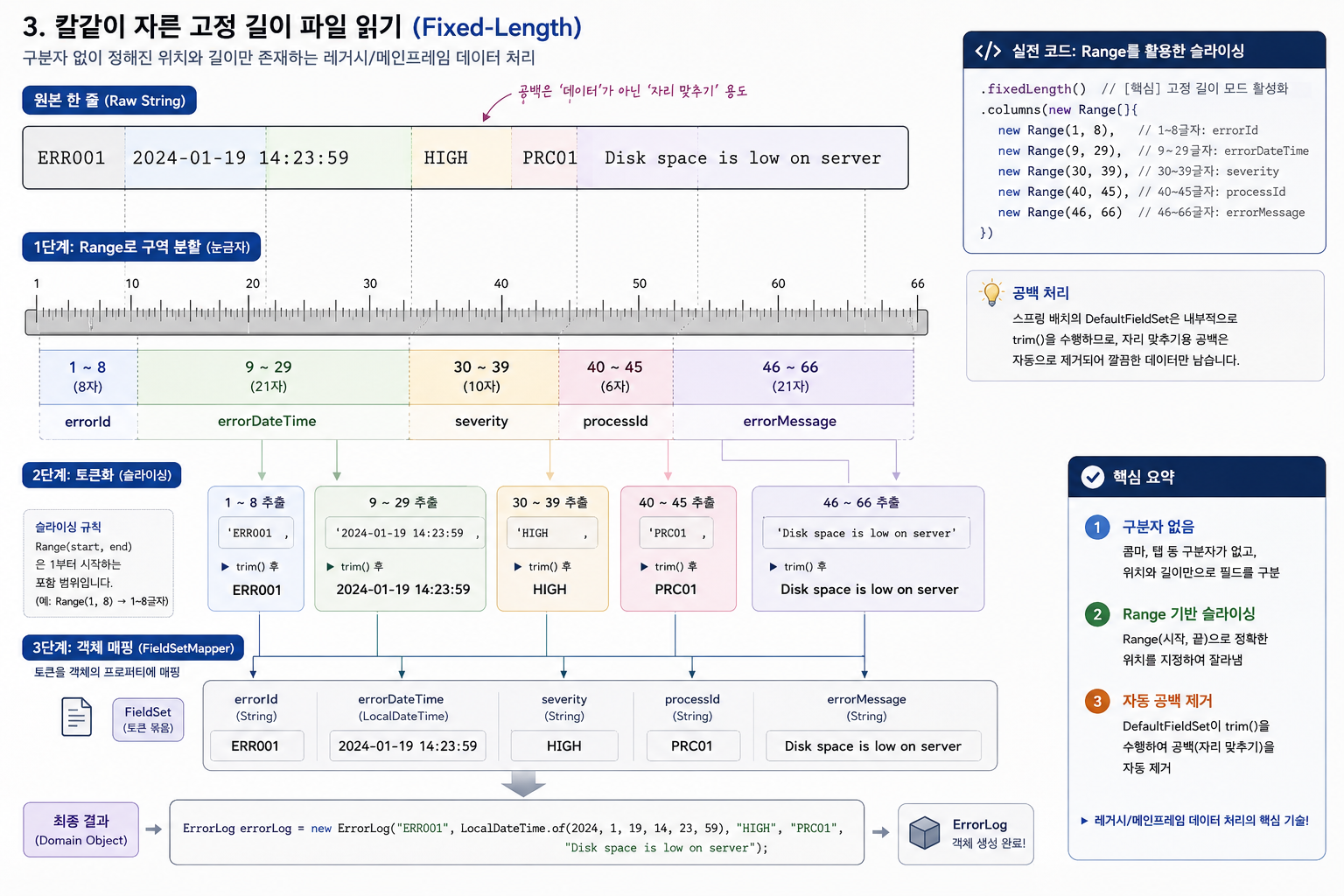
@Bean
@StepScope
public FlatFileItemReader<SystemFailure> systemFailureItemReader(
@Value("#{jobParameters['inputFile']}") String inputFile) {
return new FlatFileItemReaderBuilder<SystemFailure>()
.name("systemFailureItemReader")
.resource(new FileSystemResource(inputFile))
.fixedLength()
.columns(new Range[]{
new Range(1, 8), // errorId: ERR001 + 공백 2칸
new Range(9, 29), // errorDateTime: 날짜시간 + 공백 2칸
new Range(30, 39), // severity: CRITICAL/FATAL + 패딩
new Range(40, 45), // processId: 1234 + 공백 2칸
new Range(46, 66) // errorMessage: 메시지 + \\n
})
.names("errorId", "errorDateTime", "severity", "processId", "errorMessage")
.targetType(SystemFailure.class)
.build();
}- 공백 처리: 스프링 배치의 DefaultFieldSet은 내부적으로 trim()을 수행하므로, 자리 맞추기용 공백은 자동으로 제거되어 깔끔한 데이터만 남는다.
4. 고도의 매핑 기술: Java Record와 커스텀 타입
📦 RecordFieldSetMapper: Record 매핑 지원
최신 Java의 record는 불변 객체로서 배치 도메인 모델에 최적이다. targetType()에 record 클래스를 전달하면 배치는 내부적으로 RecordFieldSetMapper를 사용하여 모든 필드를 인자로 받는 생성자를 호출한다.
public record SystemDeath(String command, int cpu, String status) {}
// Builder 설정 시
.targetType(SystemDeath.class) // 내부적으로 RecordFieldSetMapper 작동
📦 LocalDateTime 타입 변환 전략
문자열 날짜를 바로 LocalDateTime 객체로 받고 싶다면 customEditors를 사용한다.
.customEditors(Map.of(LocalDateTime.class, new PropertyEditorSupport() {
@Override
public void setAsText(String text) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
setValue(LocalDateTime.parse(text, formatter));
}
}))
5. 복잡한 패턴을 지배하는 특수 리더
🔍 RegexLineTokenizer: 정규식 기반 데이터 추출
로그 파일처럼 데이터가 []로 감싸져 있거나 가변적인 경우 정규식을 사용하여 원하는 그룹만 정확히 캡처한다.
// [WARNING][Thread-156][CPU: 78%] 메시지... 형태의 로그 분석
RegexLineTokenizer tokenizer = new RegexLineTokenizer();
tokenizer.setPattern("\\\\[\\\\w+\\\\]\\\\[Thread-(\\\\d+)\\\\]\\\\[CPU: \\\\d+%\\\\] (.+)");
🔍 PatternMatchingCompositeLineMapper: 혼합 형식 처리
하나의 파일 안에 여러 종류의 데이터 형식이 섞여 있을 때 사용한다.
- LEGACY: 타입,파일명,작성일...
- HAUNTED: 타입,파일명,작성자코드... 라인의 시작 패턴(LEGACY*, HAUNTED*)을 감지하여 각기 다른 토크나이저와 매퍼를 매칭해 하나의 객체 스트림으로 통합한다.
6. MultiResourceItemReader: 여러 파일 일괄 처단
날짜별로 분할된 수많은 거래 내역 파일을 순차적으로 읽어야 할 때 사용한다. 실제 읽기 로직은 기존에 만든 리더(delegate)에게 맡기고, 자신은 파일 목록과 정렬 순서만 관리한다.

@Bean
public MultiResourceItemReader<SystemFailure> multiReader() {
return new MultiResourceItemReaderBuilder<SystemFailure>()
.name("multiReader")
.resources(new Resource[]{
new FileSystemResource("data/fail_01.csv"),
new FileSystemResource("data/fail_02.csv")
})
.delegate(systemFailureFileReader()) // 실제 읽기를 수행할 단일 파일 리더 위임
.comparator(Comparator.comparing(Resource::getFilename)) // 파일명 순서로 정렬
.build();
}
7. 마무리하며: 지식의 Core Dump
이번 장에서는 시스템의 마지막 기록을 읽어내는 FlatFileItemReader의 기법을 알아봤다.
- 표준화: LineMapper 구조를 통해 문자열을 객체로 변환하는 규격을 읽었다.
- 다양성: CSV, 고정 길이, 정규식 등 현존하는 대부분의 파일 포맷 처리법을 파악했다.
- 안전성: 엄격한 검증(strict)과 커스텀 에디터를 통해 데이터의 무결성을 확보했다.
'Spring > Batch' 카테고리의 다른 글
| [Spring Batch] 스프링 배치 JSON 읽기/쓰기 전략 (0) | 2026.05.11 |
|---|---|
| [Spring Batch] 객체를 파일로 변환시키는 FlatFileItemWriter (0) | 2026.05.10 |
| [Spring Batch] Listener를 통한 전처리 및 후처리 (0) | 2026.05.08 |
| [Spring Batch] 잡 파라미터와 Scope로 제어하는 배치 생명주기 (0) | 2026.05.07 |
| 스프링 배치 스텝(Step)의 두 가지 유형: Tasklet vs Chunk 지향 처리 (0) | 2026.05.07 |



